Brain Activation Analysis
Predicting neural responses to visual and textual content
Drag to rotate, scroll to zoom.
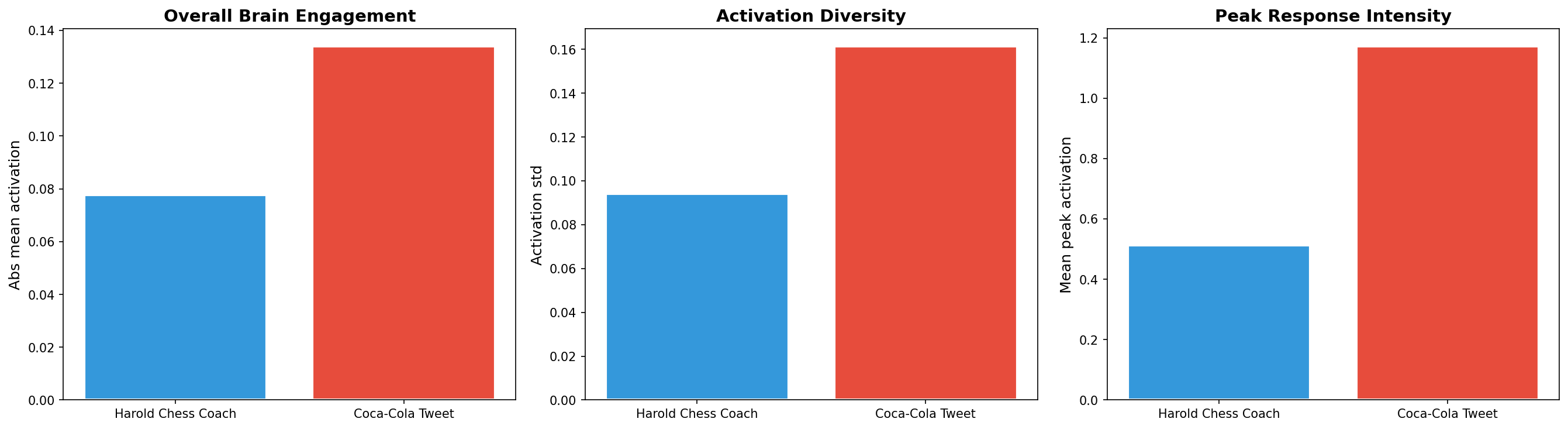
Subject B generates approximately 2x stronger neural response across all measured dimensions


Drag to rotate, scroll to zoom.
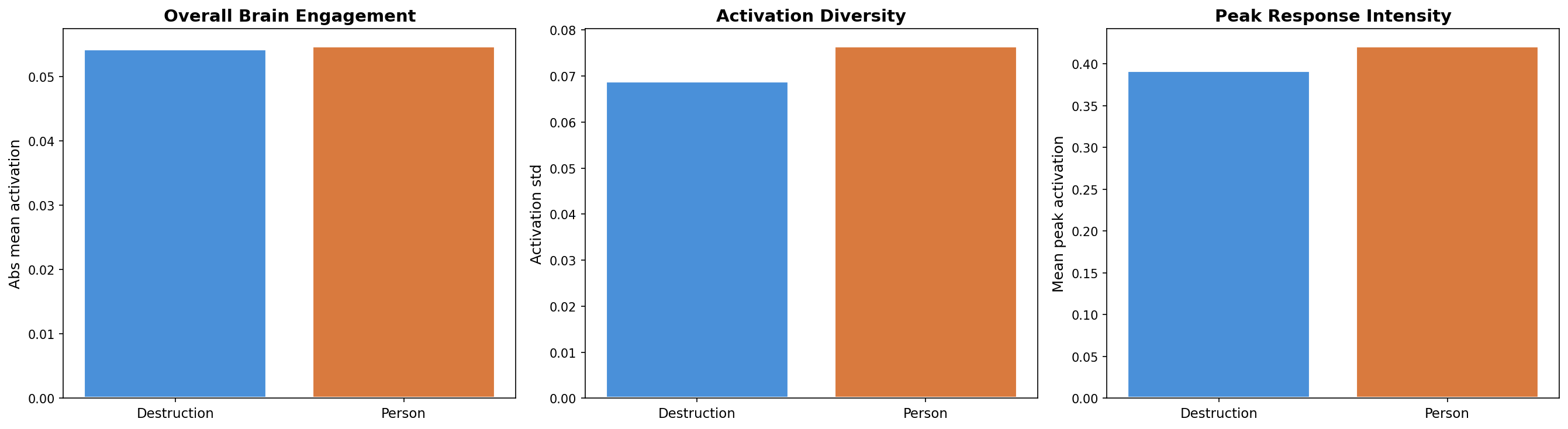
War and beach activate the brain equally strongly — but through completely different pathways
Drag to rotate, scroll to zoom.
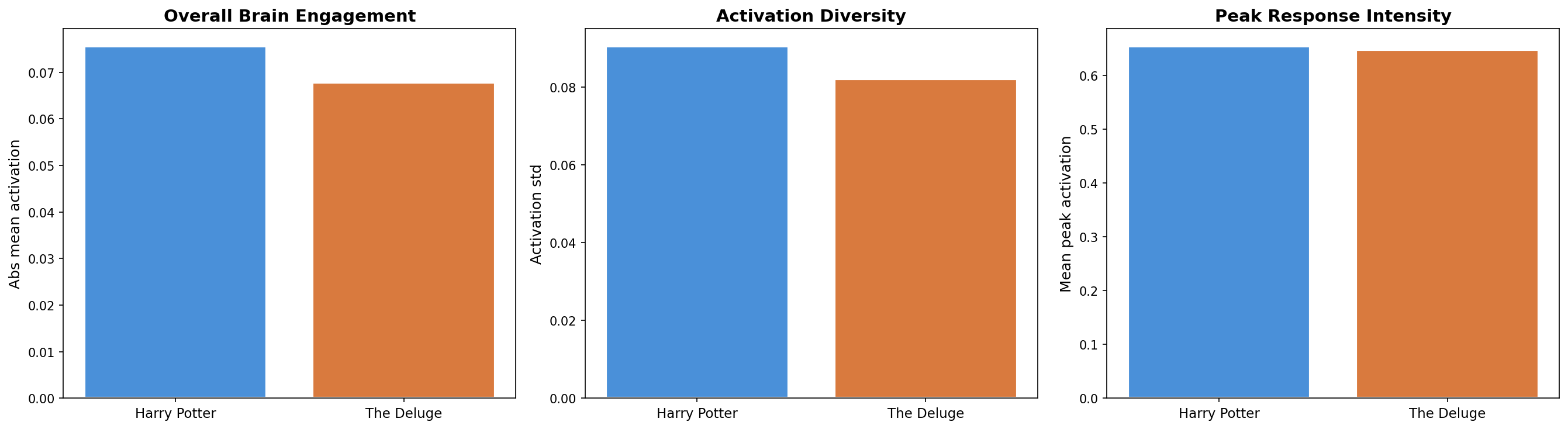
Harry Potter edges out The Deluge by ~10% in brain engagement — but peak intensity is virtually identical
Drag to rotate, scroll to zoom.
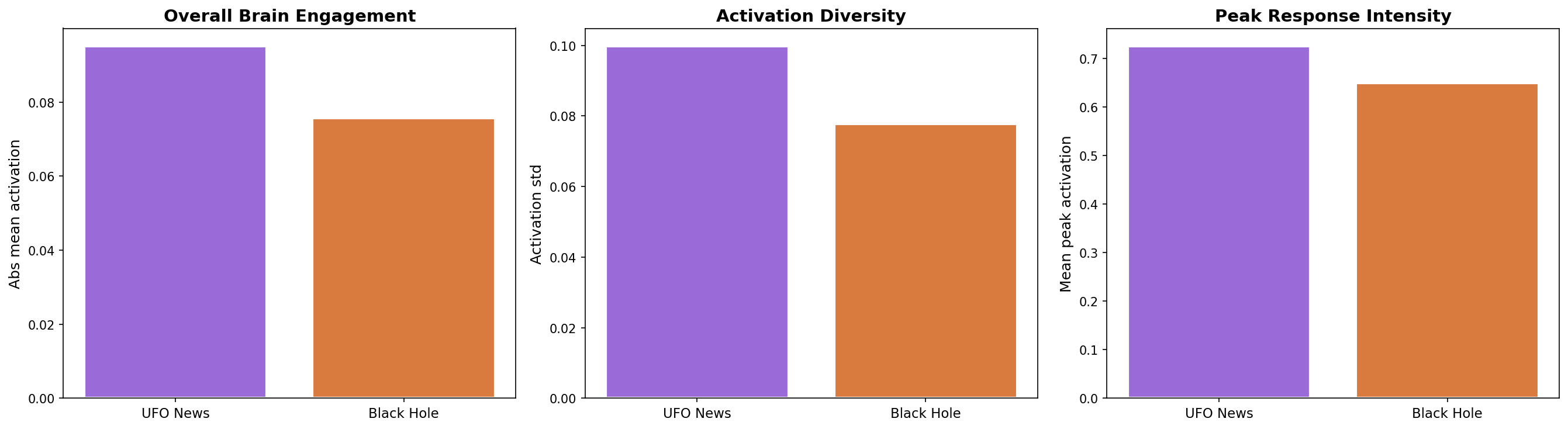
The UFO story activates the brain ~26% more intensely than the black hole discovery
About This Experiment
How we predict what the brain sees, reads, and feels
This experiment uses a deep neural network trained on real fMRI brain scans to predict how the human cortex responds to different stimuli. The model learns the mapping between content (text, images, video) and the blood-oxygen-level-dependent (BOLD) signal measured across 20,484 cortical vertices on the fsaverage5 brain surface. What you see in the 3D viewer is not a simulation — it is a data-driven prediction of actual neural activity patterns.
The predictions are generated by TRIBE v2, a multimodal brain encoding model developed by Meta AI Research (FAIR). TRIBE was trained on thousands of hours of fMRI recordings from subjects watching videos, listening to audio, and reading text. It combines visual encoders (image/video), language models (word embeddings), and audio features into a unified cortical prediction framework. The research paper is available on arXiv.
I built this tool to answer a simple question: what makes content neurally engaging? By comparing brain responses to different stimuli — viral tweets vs. product announcements, war photography vs. beach scenes, bestselling novels vs. historical epics — I can measure which content activates the brain more intensely, in which regions, and why. This is neuroscience applied to content strategy.
Each experiment follows the same flow: input content is converted to the format TRIBE expects (text → TTS audio → word events, images → short video), features are extracted through deep encoders (Wav2Vec, HuggingFace vision transformers, language models), and the brain response is predicted across the cortical surface. Per-region activations are computed using Gaussian-weighted averaging around anatomical landmarks.